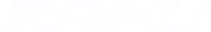
Which RPC Provider is Right For Me?

What’s covered in this guide?
Part 1: Introduction - What an RPC is. The bridge between your app and blockchain - but there's serious infrastructure complexity hidden behind that simple concept.
Part 2: The three jobs every RPC does: Read data, write transactions, stream updates. Different providers excel at different jobs.
Part 3: Reading Data - Current and Historical: Why location matters, how providers store history, and what makes some queries 20x faster than others.
Part 4: Writing Transactions - Getting them to land: why valid transactions still fail, how validator stake creates priority lanes, and multi-path routing explained.
Part 5: Streaming Updates - Real-Time without polling: Push notifications vs constant asking, when you need which approach, and why losing connection matters.
Part 6: Choosing your provider: Match your actual problem to what each provider does best. Clear decision framework.
————————————
Introduction
An RPC is the bridge between your application and the blockchain. Every time your app reads a wallet balance, submits a transaction, or checks if something is confirmed, it's going through an RPC node. At its simplest, it's just a server that listens to your requests and talks to the blockchain on your behalf.
But that's where the simple ends.
Solana produces a block every 400 milliseconds. Transactions don't sit in a mempool waiting patiently, they get forwarded directly to whoever is leading the current slot.
- If that forwarding fails or gets deprioritized, your transaction disappears with no error, no confirmation, nothing.
- Historical data can span terabytes and requires infrastructure decisions that have nothing to do with answering getBalance.
- Real-time state changes need a persistent connection architecture that standard JSON-RPC was never designed for.
What an RPC Provider actually does
"Which RPC is best?" is an unanswerable question because different providers have made different bets on which of these three jobs to do well.
- Read: Getting data from the chain, both current and historical. What's this wallet's balance right now? What transactions did it make 6 months ago? Sounds simple until you're querying a node on the other side of the world, asking for data that was pruned weeks ago, or scanning millions of accounts at once.
- Write: Getting your transaction into a block. Most developers assume that if their transaction is valid, it will land. It won't always. On Solana, there's no mempool, your transaction goes directly to whoever is producing the current block, competes with thousands of others for priority, and if it loses that competition, it simply disappears.
- React: Knowing the instant something happens onchain without constantly asking. A token price changes. A position gets liquidated. A new mint drops. You need to know immediately, not after polling every second and maybe catching it, maybe not. How providers solve this ranges from basic WebSockets to raw validator shreds, and the difference between them is measured in hundreds of milliseconds.
No provider does all three equally well. The right choice is knowing which one is your actual bottleneck.
Reading onchain data
How well a provider handles read performance comes down to where their nodes are physically located, how close they sit to the validators producing blocks, how they store and serve historical data, and what higher-level APIs they layer on top of raw RPC.
1. Geographical Location
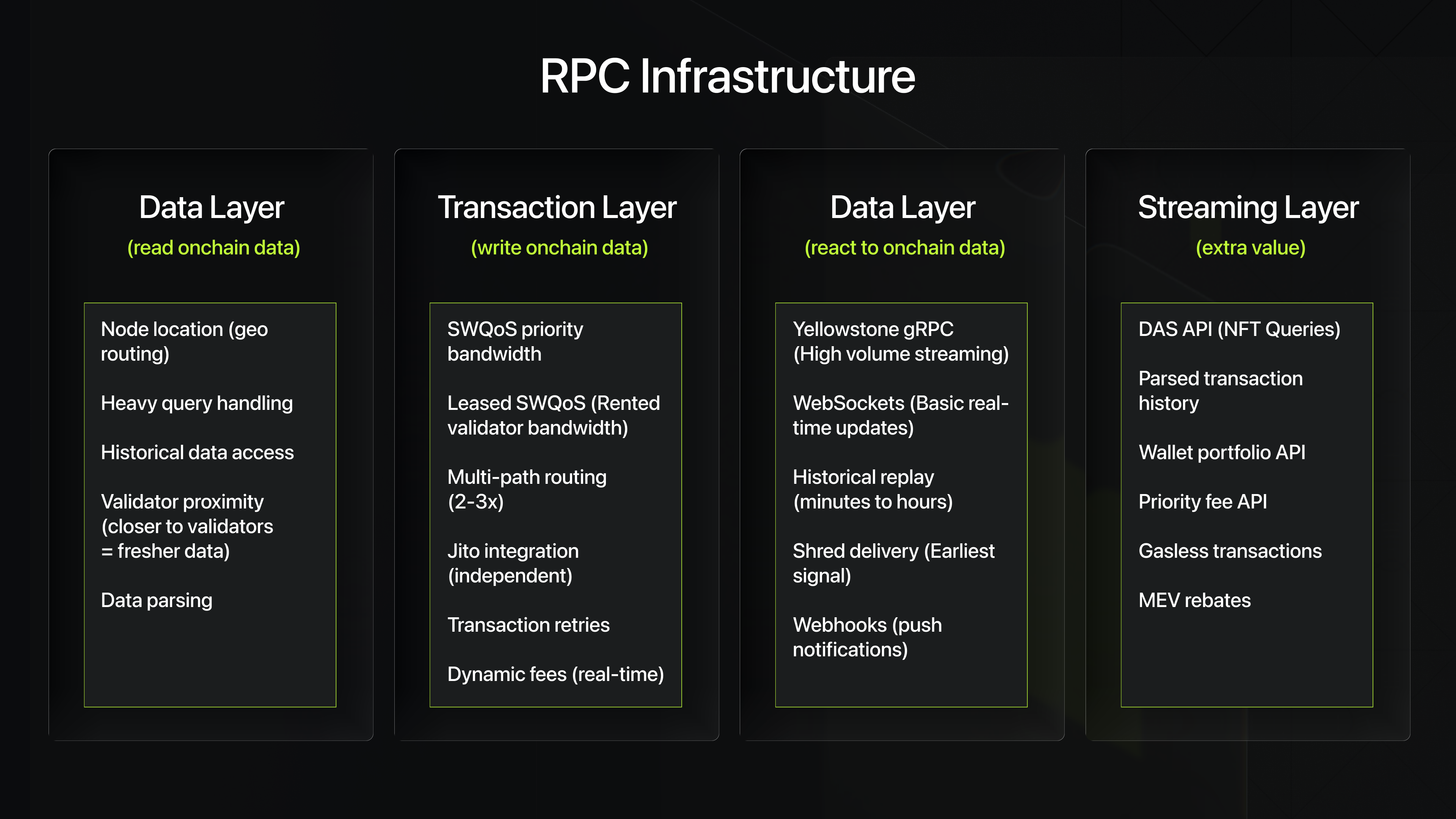
Every RPC node has a physical location, a data center, in a specific city, in a specific country.
When your app queries an RPC node, that request travels through fiber cables at roughly 200,000 km/s. A round trip from Singapore to a node in New York takes around 170ms, nearly half a Solana slot just in travel time. By the time your data arrives, the chain has already moved on.
Central Europe is the most important region in the Solana infrastructure. A large share of Solana validators chose to host their hardware there, excellent data centers, low-latency fiber across Europe, and proximity to other validators means block data propagates faster. Data arrives there before most other locations.
GetBlock RPC provider independently verified by CompareNodes benchmarking at sub-20ms across Europe, as low as 14ms in Zurich and 16ms in Frankfurt, with a global average below 100ms. Nodes across Frankfurt, New York, and Singapore with automatic geo-routing.
Helius: 11 regions across 3 continents: North America (Pittsburgh, Newark, Salt Lake City, Los Angeles, Vancouver), Europe (Dublin, London, Amsterdam, Frankfurt), Asia (Tokyo, Singapore), with automatic routing to the nearest node. Also offers Gatekeeper in beta, replaces Cloudflare with their own edge layer for significantly lower latency.
2. Node Proximity to Validators
When Solana produces a block, it doesn't broadcast the complete block all at once. It breaks it into small fragments called shreds and distributes them through the network using a protocol called Turbine. This distribution follows a stake-weighted tree, validators with the most stake sit at the top and receive shreds first, then pass them down to lower-stake validators.
This means two things. First, where your RPC node sits in relation to high-stake validators directly affects how fresh your data is. A node physically close to top validators receives block data earlier than one sitting further down the tree. Second, a provider that actually runs high-stake validators gets data at the source, before it's been passed down through multiple hops.
How the RPC provider approaches it:
Helius is the largest staked validator on Solana at 14.5M SOL, sitting near the top of the Turbine distribution tree, meaning block data reaches their nodes earlier than most, which directly translates to fresher data on their RPC endpoints.
3. Archival Infrastructure
When you run a Solana node, it doesn't keep everything forever. Storing the complete history of every transaction since genesis would require terabytes of storage, growing every single day. So standard nodes prune, they delete old data and only keep the recent state (by design, roughly the last 2 epochs with default settings).
This is fine for real-time operations. The moment you need anything historical, a wallet's transaction history, a trade from 3 months ago, an analytics query spanning 6 months, Solana relies on its separate archival system for full long-term history. This was originally built on Bigtable, Google's managed database that the Solana Foundation selected for long-term storage of complete transaction data from genesis. It works but throttles under heavy load, scans from oldest data first (making recent queries slower than they need to be), and can have gaps under certain failure conditions.
RocksDB handles what fits on a normal node; Bigtable handles everything beyond that (the true historical archive).
How the provider approaches it:
Helius owns and operates dedicated archival nodes completely separate from its standard RPC fleet. Historical queries hit this dedicated infrastructure rather than being routed externally. Their getTransactionsForAddress method queries this layer directly.
Alchemy rebuilt its entire historical data layer from scratch after acquiring DexterLab in 2025. They replaced Bigtable with HBase, self-hosted, globally distributed, recency-first scanning. Instead of traversing from the genesis to find recent transactions, it starts from the most recent data. No throttling, no gaps.
Triton uses a three-tier approach: local ledger first, then internal cache, then Bigtable as a final fallback. Only Bigtable hits incur extra charges. Their next-gen replacement, Old Faithful, is open source and currently available via a separate path before becoming their standard backend.
QuickNode handles historical data through Streams. Instead of querying historical data directly, you define what you want with a JavaScript filter, and it delivers matching data to your storage system, backfilling from any point in the chain's history.
4. Parsing & Querying Transaction Data
4.1 Data Abstraction
On Solana, transactions are stored as low-level, binary-encoded instructions and account state changes. They are machine-readable, not application-readable.
Applications, however, require semantic meaning, who transferred what, which swap occurred, which NFT was sold, what accounts were affected.
Some providers place this abstraction at the API layer, returning fully decoded, labeled transaction data, this is the approach used by Helius. Others expose high-performance raw data streams, where abstraction is implemented within your own infrastructure stack, this is the model used by Triton One.
4.2 Heavy Program Queries: Scanning every account owned by a program is one of the most expensive operations on Solana, standard nodes frequently timeout or return errors under real load.
Alchemy built dedicated AccountsDB infrastructure handling these scans 10x faster with pagination so large datasets don't timeout. Triton built Steamboat, a dedicated indexing layer that creates custom indexes tailored to your specific query pattern.
4.3 Complete Wallet Picture: Getting a full wallet view normally means stitching together multiple separate calls, SOL balance, token balances, NFT holdings, transaction history, and joining the results yourself.
4.4 Priority Fee Estimation: Too low a fee and your transaction fails during congestion. Too high and you overpay. Dynamic fee APIs analyze what fees actually landed in recent blocks for your specific program, not network-wide averages.
Write data onchain
Most developers assume that if their transaction is valid, it will land. On Solana, that assumption breaks constantly. The reason comes down to how Solana actually processes transactions, and it's fundamentally different from every other chain most developers have worked with.
Why do transactions fail sometimes?
Sending a transaction on Solana feels instantaneous, and it is. But that speed comes with a tradeoff. There's no waiting room, no queue, no safety net. The moment you submit, your transaction is in a race, and several things can knock it out before it ever lands.
- No Mempool: On Ethereum, transactions sit in a mempool waiting for their turn. Solana has no mempool. The moment you send a transaction, it gets forwarded directly to whoever is producing the current block, right now. If that validator is overwhelmed, if your connection isn't prioritized, if the forwarding fails, the transaction disappears.
- Blockhash Expiry: Every Solana transaction contains a recent blockhash that acts as a timestamp. That blockhash expires after 150 slots, roughly 60 seconds. If your transaction hasn't landed by then, it's not pending, it's not failed, it's just dead. You need to rebuild it with a fresh blockhash and start over. During heavy congestion, where transactions are getting dropped repeatedly, you can burn through multiple blockhashes before anything lands.
- TPU Congestion: The leader's Transaction Processing Unit processes thousands of transactions per second. During high-traffic events, it gets overwhelmed and has to prioritize. Two things determine that priority: the stake weight of whoever is forwarding your transaction, and the priority fee attached. An unstaked connection with a low fee during a hot launch is essentially invisible.
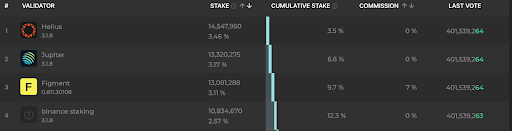
1. Stake-Weighted Quality of Service (SWQoS)
The leader's TPU doesn't treat all incoming transactions equally. It allocates bandwidth proportional to the stake weight of the forwarder of the transaction. High stakes get a dedicated priority lane. Unstaked connections share a congested lane that gets dropped first when traffic spikes. You cannot buy SWQoS access as a feature, the only way to have it is to run validators with a meaningful stake on the network.
Helius operates the #1 staked validator on Solana at 14.5M SOL. Every transaction sent through Helius gets forwarded through this validator's priority bandwidth.
Alchemy operates a validator at 2.1M SOL (0.50% of total stake).
QuickNode operates a validator at 906K SOL (0.22% of total stake) with 0% commission and 100% Jito MEV pass-through.
Triton operates a validator at 513K SOL (0.12% of total stake) and sells unused stake-weighted bandwidth through the Cascade marketplace, covered in the next point.
2. Priority Bandwidth - Leasing & Marketplaces
Running your own validators gives you SWQoS access. But some providers go further, either by leasing priority bandwidth from other validators or building marketplaces around it.
GetBlock takes a hybrid approach with LandFirst, their transaction routing layer. Rather than relying solely on their own stake, they combine three paths simultaneously: their own SWQoS connections, leased priority bandwidth from partner validators through private arrangements, and Jito block engine submission. All three run in parallel, whichever lands first wins. It's included on all plans at no extra fee.
Triton built Cascade, an open marketplace where validators list their unused stake-weighted bandwidth and applications bid for it. You purchase a specific amount of throughput in Packets Per Second, all winning bidders pay the same floor price, and allocations roll over each epoch. Transactions within your bandwidth get priority routing, anything beyond falls back to standard routes.
3. Multi-Path Routing
Sending through one path is a single point of failure. Some providers submit simultaneously through multiple independent paths, the leader takes whichever arrives first and ignores duplicates. Smart routing also checks the leader schedule before submitting, knowing who produces the next slot means routing directly toward them rather than hoping propagation gets there in time.
Helius fires two paths simultaneously, their own staked validator connections and Jito's block engine, across 7 global endpoints
GetBlock LandFirst fires three paths simultaneously: their own SWQoS connections, leased SWQoS from partner validators, and Jito. On top of that, their router analyzes the current leader schedule in real time, selecting the fastest geographic path to whoever is producing the next slot before submitting.
4. Jito Integration
Jito is a separate MEV-aware block engine running alongside the standard TPU on many Solana validators. Submitting through Jito with a small tip enters a priority queue, validators running Jito process these preferentially. It's a completely independent submission path from standard TPU routing, which is why providers combine it with their own paths rather than using it as a replacement.
5. Transaction Retries
Once you send a transaction, it either lands or disappears, there's no pending state. If it doesn't land, you need to resubmit it yourself before the blockhash expires.
The key is setting maxRetries: 0 and building your own retry loop. RPC nodes retrying on your behalf actually makes congestion worse, not better. Resubmit every few seconds with a fresh blockhash until you get a confirmation.
Two things improve your odds on each attempt: sending with skipPreflight: true opens more delivery paths, and setting a priority fee based on current rates for your specific accounts, not a broad network average, makes your transaction harder to ignore.
React to onchain data
The Polling Problem
The naive approach to knowing when something changes onchain is polling, your application asks "did anything change?" on a timer.
Say you're watching a liquidity pool for price changes:
At 0ms: You ask "What's the pool state?" - get back 1000 USDC
At 400ms: You ask again - still 1000 USDC
At 800ms: You ask again - still 1000 USDC
At 1200ms: You ask again - now it's 950 USDC
You find out 400ms late at best. You're making 9,000 calls per hour per account. Watch 100 accounts and you're burning through rate limits while still being late to every change. Streaming fixes this, instead of you repeatedly asking, the provider pushes data the instant something happens.
Geyser solves this problem
Geyser is a plugin built directly inside Solana's validator software. As the validator processes transactions, it fires internal events: account changed, transaction confirmed, block produced, before data is even packaged for standard RPC responses. Think of it as a tap into the validator itself, firing the instant something happens rather than waiting for it to be serialized and served through standard RPC.
Yellowstone (originally built by Triton One, fully open source) takes that Geyser output and exposes it externally over gRPC, a binary protocol significantly more efficient than JSON WebSockets at high volume. The same transaction data that takes 120 bytes in JSON takes roughly 35 bytes in binary. At thousands of events per second that difference is the difference between your connection keeping up and falling behind. Yellowstone became the de facto standard, every serious streaming product in the Solana ecosystem is built on top of it.
Yellowstone - How Provider Implements It
- Helius LaserStream
Managed Yellowstone built on a Richat fork, drop-in compatible with existing Yellowstone clients. The standout feature is 24-hour historical replay, 216,000 slots stored. If you disconnect for any reason, specify the slot you left off and LaserStream streams everything you missed then catches up to live. Multi-node redundancy means one node failing doesn't kill your stream. Auto-reconnection handled by the SDK. 40x faster than standard Yellowstone JS clients. 9 global regions. - Alchemy Yellowstone gRPC
Multi-producer, multi-consumer architecture, multiple Solana nodes feed the stream simultaneously, client connections load-balanced across multiple consumer endpoints. No single point of failure in the pipeline. 6,000 slot replay window (~40 minutes).
The Replay Gap
This is the issue most developers don't discover until it breaks them in production. Standard Yellowstone has no catch-up mechanism; slots that pass while disconnected are gone permanently. A deployment restart, a brief network blip, or a crash all result in permanent data loss.
- Helius LaserStream: 24 hours (216,000 slots)
- Alchemy: ~40 minutes (6,000 slots)
For a trading bot restarting in 5 seconds, this doesn't matter. For an indexer maintaining complete data integrity, it's one of the most important infrastructure decisions you'll make.
1. Shred Delivery - The Earliest Signal Possible
Standard streaming gives you data after blocks are confirmed. But Solana builds blocks in fragments that spread through the network before assembly. Tapping into raw fragments means getting data before confirmation exists.
Some providers deliver raw UDP fragments directly. You receive binary pieces and must reconstruct transactions yourself. HFT and MEV only - justified when microseconds equal profit.
Others process fragments at infrastructure level, giving you 25-30ms speed advantage without reconstruction complexity.
2. WebSockets - Browser-Compatible Streaming
Standard subscriptions for watching accounts, programs, and transactions in real-time. Works natively in browsers. Perfect for frontend apps and moderate-volume backends.
Limitation: JSON parsing becomes a bottleneck at high volume. That's when you switch to gRPC.
Better providers add server-side filtering - only matching data travels to you, saving bandwidth.
3. Webhooks - No Connection Required
Give the provider a URL, they POST when events happen. No connection to maintain, automatic retries if your server is down.
Perfect for: notifications, database writes, Discord alerts. Anything where you react to events but don't need sub-second speed.
Some providers offer parsed data, raw binary, or platform-specific formatting. Others let you define filtering logic server-side.
Shred Delivery: Earliest signal, hardest to use, HFT only
gRPC/Yellowstone: High volume, production backends
WebSockets: Moderate volume, frontend apps
Webhooks: No connection needed, notifications
Push Pipelines: Filtered historical plus real-time
How to Choose
The right provider depends on what’s actually breaking for you. Not benchmarks, not feature lists, your specific bottleneck.
- If transactions aren’t landing reliably
Look for providers running validators with meaningful stake. Check for multi-path routing features, simultaneous submission through multiple independent paths. Some offer bandwidth marketplace access where you can lease additional priority capacity. - If you’re losing streaming data on disconnect
The replay window is critical. Options range from 40 minutes to 24 hours to unlimited guaranteed delivery models. No replay buffer means any disconnect equals permanent data loss. - If historical queries are slow or failing
Find out if they own archival infrastructure or outsource it. Owned infrastructure (especially custom-built systems like HBase) delivers 10-20× faster queries with no gaps. - If you’re building on NFT or token data
DAS API maturity varies significantly. Check coverage for your specific asset types — standard NFTs, compressed NFTs, MPL Core, Token 2022. - If geographic latency is critical
Check provider positioning in high-stake validator regions. Some offer custom geolocated deployment on dedicated plans. - If you need enterprise compliance
Look for SOC 1 Type 2, SOC 2 Type 2, and ISO 27001 certifications if regulatory compliance matters.


